Comparison
Higgs TTS vs VibeVoice (2026): The Most Comprehensive AI Voice Model Comparison
By Ethan Liu, Senior Audio Tools Editor · Audio comparisons with Mia Chen · Updated June 22, 2026
We compared Higgs TTS and VibeVoice across text-to-speech, voice cloning, latency, long-form coherence, multi-speaker, and multilingual output — with real A/B audio from both. The short version: they solve different problems.

Quick answer
Higgs TTS and VibeVoice aren't direct competitors — they sit in two different layers of AI voice generation. Higgs TTS is a real-time text-to-speech and voice cloning system for production apps. VibeVoice is a research-oriented, long-form multi-speaker model for podcast-style and dialogue synthesis. Pick Higgs for real-time speech and cloning; pick VibeVoice for long-form, multi-speaker audio.
The reason they keep getting compared is that both turn text into natural-sounding speech, and both surfaced in the same 2026 wave of generative audio. But the moment you look at how each is deployed — an API you call in real time versus a model you run to render long audio offline — the overlap mostly disappears. The rest of this comparison walks through where that difference actually shows up, backed by audio you can play yourself.
Why this comparison matters in 2026
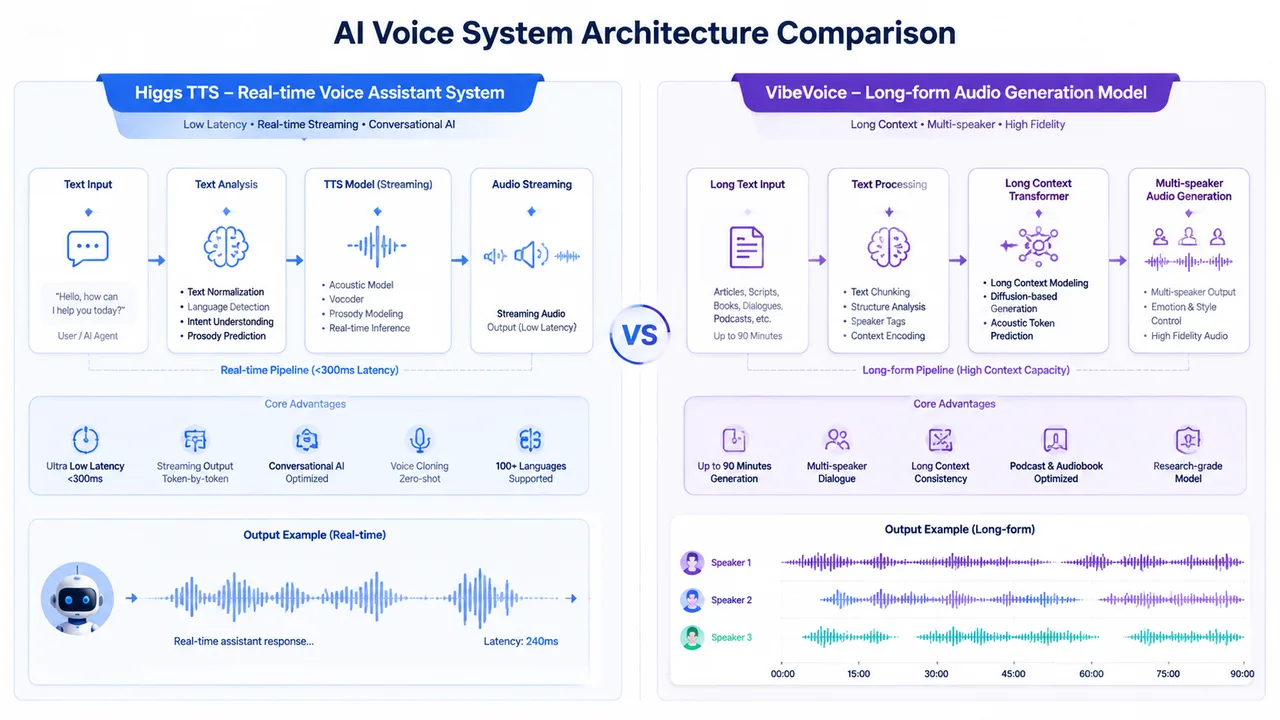
Modern AI voice has split into two directions. Real-time systems (the interaction layer) power assistants, chatbots, and customer service; long-form systems (the content layer) power podcasts, audiobooks, and dialogue research. Higgs TTS lives in the first layer; VibeVoice in the second. That framing explains nearly every difference below.
A real-time system is judged on latency, voice consistency, and how it sounds in a back-and-forth exchange — the user is waiting on the other end. A long-form system is judged on coherence across minutes of audio, speaker separation, and how natural a sustained narration feels. Optimizing hard for one usually costs you the other, which is why no single model tends to win both. Keeping that trade-off in mind is the fastest way to read the table and tests that follow without over-weighting any one "winner" label.
What is Higgs TTS?
Higgs TTS is a production-oriented system combining text-to-speech and voice cloning. It runs a standard neural TTS pipeline — text processing, phoneme conversion, speech synthesis, waveform generation — tuned for expressive, multilingual, low-latency output. It targets AI voice assistants, real-time chatbots, multilingual apps, and voice cloning services. Exact architecture details vary by deployment version and aren't fully standardized publicly.
In practice, the thing that defines Higgs TTS is that it behaves like infrastructure: you send text, you get speech back fast enough to drop into a conversation, and the voice you picked stays the same call after call. That predictability — plus reference-based cloning and broad language coverage — is what makes it a fit for shipping products rather than one-off renders.
What is VibeVoice?
VibeVoice is a research-oriented long-form speech generation model for multi-speaker audio and long-context modeling (source: arXiv paper 2508.19205). Its verified contributions include long-context synthesis (research experiments up to ~90 minutes), multi-speaker modeling (up to 4 speakers as reported), and a high-compression speech tokenizer (~80× efficiency vs baseline codecs). Importantly, it is not a real-time TTS system or a production voice API — it is primarily a research model.
What stands out about VibeVoice is scope: it is built to hold a single coherent voice — or a handful of distinct voices — across very long stretches of audio, which is a genuinely hard problem for speech models. The trade-off is that this strength lives offline. You render the audio rather than stream it, so it shines for produced content and research, not for the live, low-latency interactions Higgs TTS targets.
Feature-by-feature comparison
Where each system wins, based on design focus and documented capability.
| Dimension | Higgs TTS | VibeVoice | Winner |
|---|---|---|---|
| Text-to-speech | Standard real-time TTS pipeline | Not a TTS system | Higgs TTS |
| Voice cloning | Reference-based, stable identity | Speaker consistency, not cloning-first | Higgs TTS |
| Real-time / latency | Low-latency streaming output | Batch, long-context generation | Higgs TTS |
| Long-form coherence | Stable, can flatten over length | Strong long-context (research up to ~90 min) | VibeVoice |
| Multi-speaker | Dialogue via text | Up to 4 speakers (per paper) | VibeVoice |
| Multilingual | Multilingual, global focus | Exists, not the core focus | Higgs TTS |
| Expressive / emotional | Prosody & style control | Structure over emotional variation | Higgs TTS |
Read down the winner column and the pattern is clear: Higgs TTS takes the dimensions tied to live interaction — latency, voice cloning, multilingual reach, and expressive control — while VibeVoice takes the two tied to sustained content, long-form coherence and multi-speaker dialogue. There is no row where both lose, and only a couple where they truly contest the same ground, which again reflects that they were built for different jobs rather than to beat each other on a single benchmark.
Real-world hands-on testing
Beyond documentation, we ran both systems on three tasks and kept the actual output. Listen to the A/B samples below — this reflects practical behavior, not spec claims.
Each test used the same input text for both systems, default voice settings, and no post-processing or cleanup on the audio. We chose tasks that map to the dimensions above: a short conversational line for real-time feel, a multi-paragraph passage for long-form coherence, and a reference-then-clone task for speaker consistency. Your own script is the best judge, but these clips show the tendencies we heard repeatedly.

Test 1: Short conversational sentence
Prompt: “Hey, can you explain how AI voice models work in simple terms?”
Higgs TTS: Feels like a real assistant conversation — natural pauses, neutral clarity, and delivery that sounds spoken rather than read aloud. The cadence lands close to how a person would actually answer the question in a live chat.
VibeVoice: Clear and intelligible, but more narration-like: fewer dynamic pauses and a slightly more robotic tone on short, conversational lines. It reads the sentence correctly rather than performing it as dialogue.
Winner: Higgs TTS
Test 2: Long-form paragraph (news style)
Prompt: A 2–3 paragraph technology news summary about AI trends.
Higgs TTS: Stays stable across the full passage and never loses the thread, but the tone flattens a little over multiple paragraphs — it prioritizes consistent clarity over narrative momentum, which suits UI prompts and shorter replies.
VibeVoice: Noticeably better paragraph-to-paragraph continuity and long-context stability. The pacing and intonation carry across sentences the way a podcast host or audiobook narrator would — exactly what it was designed for.
Winner: VibeVoice
Test 3: Voice cloning consistency
Prompt: A short 10–15 second reference voice sample, then new text in that voice.
Higgs TTS: High similarity to the reference voice, with a stable timbre across repeated generations and minimal pitch or identity drift. Re-running the same text produced consistent results — important for branded or recurring voices.
VibeVoice: Captures the broad character of the reference, but with more variation between generations and occasional emotional tone shifts. Usable, yet less predictable when you need the exact same voice every time.
Winner: Higgs TTS
Which one should you choose?
Choose Higgs TTSfor an AI voice assistant, a SaaS voice API, a voice cloning product, real-time chatbot voice, a multilingual AI agent, or any production system integration — it's a product-grade voice engine.
Choose VibeVoicefor podcast generation, audiobook synthesis, long dialogue scripts, research experiments, or multi-speaker storytelling — it's an audio generation engine. Many teams could use both: Higgs for the interactive voice layer, VibeVoice for long-form content.
A useful tie-breaker: ask whether a human is waiting on the other end of the audio. If yes — a caller, a chat user, an agent mid-conversation — you need real-time output and stable identity, so Higgs TTS is the right tool. If no — you are producing an episode, a chapter, or a scripted dialogue to be published later — you can trade latency for VibeVoice's long-form polish. That single question resolves most real decisions faster than any feature checklist.
Limitations of each
- Higgs TTS: long-form narrative isn't its primary focus, deployment depends on configuration, and cloning quality tracks reference-audio quality.
- VibeVoice: not real-time, not a production API, and research-oriented — powerful for long-form generation but not built for low-latency apps.
Final verdict
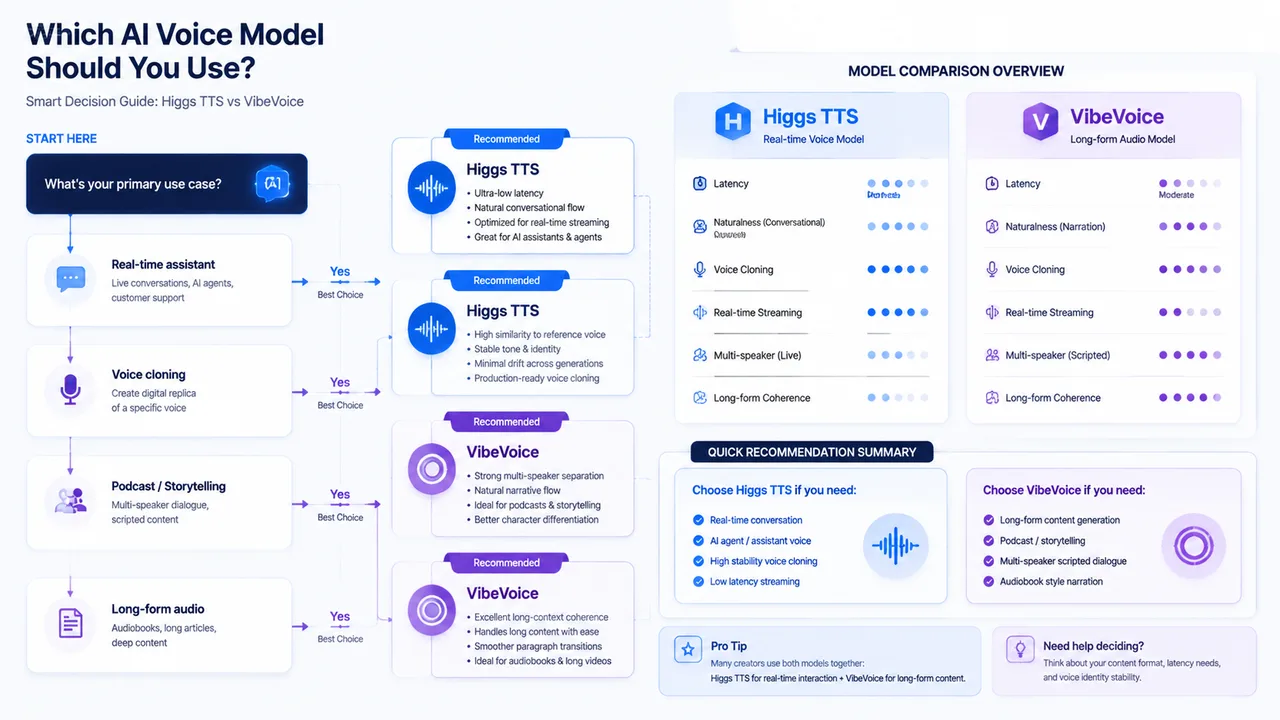
These models operate in different layers, so "better" depends entirely on the job. For real-time text-to-speech, voice cloning, multilingual output, and production AI voice, Higgs TTS is the stronger pick. For long-form audio, multi-speaker dialogue, and research-level experimentation, VibeVoice leads. If your goal is building real-time conversational voice in 2026, start with Higgs Audio v3 TTS — 3 free credits, no install. See pricing for credit packs.
FAQ
Higgs TTS vs VibeVoice — frequently asked questions
What is Higgs TTS used for?▼
Higgs TTS is used for real-time text-to-speech and voice cloning — AI assistants, chatbots, multilingual voice apps, and production content workflows.
What is VibeVoice?▼
VibeVoice is a research-oriented, long-form multi-speaker speech generation model (arXiv 2508.19205) aimed at podcast-style and long dialogue synthesis — not a real-time production TTS API.
Is VibeVoice a TTS system?▼
Not in the traditional sense. It generates long speech sequences directly and models audio as a continuous generative process, rather than running a standard text-to-speech pipeline.
Which is better for real-time use and voice cloning?▼
Higgs TTS. It is built for low-latency streaming and reference-based voice cloning with stable speaker identity, which fits assistants and production apps.
Which is better for long audio and multiple speakers?▼
VibeVoice. Its long-context modeling and up-to-four-speaker support (per the paper) make it stronger for podcasts, audiobooks, and multi-speaker dialogue.
Try Higgs TTS yourself
The fastest way to compare is your own script. Start with 3 free credits — no install.